stable diffusion
4,2 gigabyte open source um jedes erdenkliche bild zu erzeugen

("photograph of a young woman painting an artwork on the berlin wall that shows snoopy, high details", seed 265)
("photograph of a young woman painting an artwork on the berlin wall that shows snoopy, high details", seed 265)
| kleine anmerkung: diese seite habe ich im september und oktober 2022 geschrieben. wenn das lange zurück liegt könnte der inhalt debil erscheinen, weil ich total altbackene technologie anpreise : / |
die software
seit august 2022 gibt es erstmals einen wirklich komplett freien text-zu-bild generator: "stable diffusion". jeder kann sich die open source software und das datenmodell kostenlos runterladen und vollständig lokal auf einem handelsüblichen rechner laufen lassen. der rechner sollte allerdings eine mittelgute grafikkarte haben, denn sonst dauert das rechnen wohl sehr lang. man muß nur python installieren, einen huggingface account anlegen, die sehr sehr freie lizenz akzeptieren und ein token generieren. wie's genau geht steht auf huggingface.co/blog/stable_diffusion .
noch einfacher geht es mit meinem kleinen selbstgebastelten python script sd.txt (mußt du in sd.py umbenennen). da generiere ich bilder in einer schleife, was mit ner RTX 3070 grafikkarte pro bild nur um die 10 sekunden dauert. das script ist zum ausprobieren und basteln. wer etwas python kann, wird sich schnell zurechtfinden. für alle anderen gibt es zum online ausprobieren huggingface.co/spaces/stabilityai/stable-diffusion . der eingabetext (englisch "prompt") kann natürlich auch in deutsch sein.
text = bild
die einfachste variante ist, daß man einen text wie "frau malt snoopy auf die berliner mauer" eingibt und bilder wie das oben rauskommen. die funktion habe ich september 2022 ausgiebig getestet und gelungene beispiele auf sechs durchgehend verlinkten seiten geklebt:
beispiele 1 (laptop, huhase, lady di, wolfmaus, roboter, kermit, achterbahn, kind, ballon)
beispiele 2 (neandertaler, techno club, loveparade, fee)
beispiele 3 (schäfchenwolken, schwein, priester, schiele, snoopy)
beispiele 4 (drogenvisionen, mädchen und großvater)
beispiele 5 (raumschiff, ameise und spinne, doppelgängerwettbewerb, alice, nixon, nixe)
beispiele 6 (sirene, vampir, zombie, känguru, geist, fehler, absturz)
meine tips dazu:
ergebnisse werden viel besser, wenn man dazu schreibt wo! etwas sein soll und daß man viele details möchte. also indem man etwa "at a public playground, high details" an den text anhängt. der parameter guidance_scale ist bei 6.8 ziemlich optimal eingestellt. der hat aber großen einfluß. das bild (mit dem gleichen seed) ändert sich stark bei niedrigeren werten und bei höheren vereinfacht sich das bild zunehmend. der parameter num_inference_steps ist bei 70 ganz gut eingestellt. kleinere werte beschleunigt die berechnung. höhere werte erhöhen immer die qualität des bildes. die lassen kleine artefakte und fehler verschwinden, korrigieren schatten und sowas. man kann also erstmal mit 70 rechnen und wenn man ein bild toll findet, kann man es mit mit gleichem seed und num_inference_steps=350 nochmal in sauber rechnen. und die bilder sollten 512 x 512 pixel groß sein. alternativ eine seite 512 pixel und die andere ein vielfaches von 64 pixeln, aber das reduziert dann merklich die qualität.
bild + text = bild
man kann auch bilder als startvorgabe mitgeben und so bilder auf der basis von einem bild und einem text erzeugen. das war auch das allererste, was ich ausprobiert habe, nur hatte ich irrtümlich eine falsche pipeline benutzt, schnell aufgegeben und bilder dann nur noch aus text erzeugt.
die allerersten bilder die ich noch ohne irgendwelche feineinstellungen durch die bild-zu-bild funktion geschickt habe, waren meine pastellskizze "weinglas":

und meine total vergurkte und nachträglich extrem weichgezeichnete schnellskizze von nem wolf :

ganz begeistert von den ergebnissen habe ich dann ein paar meiner alten aktskizzen zum leben erweckt:
beispiele (NSFW, weil darstellung sinnloser nacktheit in maschinenhalluzinationen)
meine tips dazu:
der parameter num_inference_steps ändert das ergebnis. wenn man hohe werte nimmt, wird das bild also nicht nur besser, sondern auch anders. darum sollte man sich vorab auf eine anzahl berechnungsschritte festlegen. und eingangsbilder müssen farbige flächen enthalten. umrisse funktioneren nicht oder nur zufällig. um einer graphitskizze hautfarbe zu geben, malt man den körper einfach mit einem fast transparenten hautfarbenem pinsel mit so 10% deckkraft digital aus. dann weiß stable diffusion, was zum körper gehört und welche farbe der hat. es muß nicht genau sein, weil die software details ja kennt und ausgleicht.
bild + text = video
als nächstes hatte ich die idee damit kleine filme herzustellen. mein gedanke: wenn man das erzeugte bild als eingangsbild für das nächste zu erzeugende bild benutzt und die bilder hintereinandersetzt, müssten filme entstehen. als startbild habe ich meinen koyoten auf die kommode gesetzt und fotografiert:

die "ausgabebild ist nächtes eingabebild" idee habe ich dann in dem script programmiert und festgestellt, daß so erzeugte videos sehr schnell in einem stabilen vierfarbigen bild oder in rauschen enden - je nach einstellungen.
(kleiner nachtrag von 3 wochen später: das stimmte so nicht ganz, siehe kapitel "text = video" weiter unten)
was aber geht ist, ein video aus bildern für verschiedene parameterwerte. wenn man zuerst das eingangsbild stark gewichtet und dann zunehmend den text "foto von einem niedlichen freundlichen tier" (der parameter strength wandert dabei von 0.2 bis 1.0), bekommt man z.b. ein video, in dem dem koyoten erst krallen wachsen, er sich dann in verschiedenste tiere umformt und am ende zum lustigen kuhschwein wird:
inspiriert durch ein youtubevideo habe ich dann später noch ausprobiert, ob man durch minimale änderung der "latents" (innere matrizen mit bilddaten) ein fast gleiches bild raus bekommt um daraus flüssige lange videos zu machen. das klappt aber nicht, entweder es tut sich fast nichts oder das bild wechselt schlagartig. je nach einstellung. ich bin mir etwa 90% sicher, daß das am berechnungsprinzip (vielleicht an der datenreduktion mit dem unet) liegt. weiche lange videos gehen damit vermutlich nur mit richtig aufwand. man könnte halt vorab immer 10000 bilder generieren und aus denen jeweils das nächstähnliche in einer veränderungsrichtung finden. aber sowas mach ich bestimmt nicht nebenher.
video + text = video
das nächste was mir zum thema video einfiel war dann, daß ich ein handyvideo in einzelbilder zerlege, jedes bild mit dem text umrechne und dann all diese bilder wieder zu einem video zusammensetze. natürlich alles mit nem script und nicht per hand. das würde sonst ewig daueren. als eingabe habe ich ein kurzes handyvideo gedreht, das den koyoten oben einfach aus minimal unterschiedlichen perspektiven abfilmt. das daraus errechnete
sieht erwartungsgemäß aus wie eine halluzination oder ein seltsamer traum.
das ganze nochmal mit einem etwas langsameren handyvideo bei tageslicht, bei dem der koyote immer vollständig im bild war. die textvorgabe für jedes einzelbild war wieder "foto von einem niedlichen freundlichen tier":
und wenn man die unnatürlichen backen des stofftieres mit klebeband nach hinten wegklappt und statt "tier" ein " erdferkel " vorgibt, schränkt das zwar die artenvielfalt etwas ein, macht den maschinentraum aber auch etwas stabiler:
beispiel "erdferkel" im hellen
das video wäre bestimmt noch viel stabiler, wenn mein albernes stofftier irgendeinem realen tier ähnlich sehen würde, obwohl das wegkleben der backen schon viel gebracht hat. egal.
als experiment habe ich dann mal eine hose, einen pullover und ein blatt papier als kopf auf die couch gelegt,

ein sehr schlechtes kurzvideo davon gedreht und das mit dem text "albert einstein sitzt 2022 auf einer couch" rechnen lassen. albert hat die sachen, die ich ihm rausgelegt habe, auch gleich angezogen:
beispiel einstein auf meiner couch
mit angela merkel funktioniert das übrigens viel besser, weil die software von der ja informationen aus 10000000 farbfotos kennt und das darum besser zusammenkriegt. aber zeugs von lebenden personen lade ich aus datenschutzgründen nicht hoch. man weiß ja nicht, ob leute videos von sich sehen möchten, wie sie in irgendwelchen klamotten irgendwo sitzen, wo sie noch nie waren : )
meine tips dazu:
das eingangsvideo sollte immer das komplette objekt zeigen, das man umwandeln möchte. also vom stofftier sollte von den ohrspitzen bis zu den füßen alles im bild sein. und das objekt sollte dem zu erzeugenden objekt möglichst ähnlich sein. des weiße blatt papier als gesicht funktioniert vermutlich schlechter als ein hellbrauner luftballon. und auf dem eingangsvideo sollte möglichst wenig passieren, damit das ausgangsvideo stabiler wird. ein winziger langsamer schwenk, der das objekt aus leicht unterschiedlicher perspektive zeigt, reicht aus.
text = video
weil ich mehrere funktionierende weiche videos gesehen habe, in denen die kamera ins bild hinein vergrößert, habe ich dann noch eine "zoom" variante ausprobiert. ausgangspunkt dafür ist ein "bild" mit reinem rauschen:
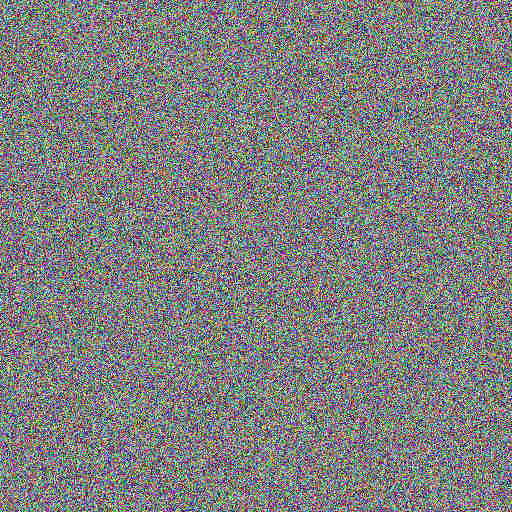
daraus zusammen mit dem text "eine lustige katze ist von neonfarbenem stoff und neonfarbenem licht bedeckt" generiere ich ein bild. das vergrößere ich etwas, drehe es etwas, verschiebe es etwas, schneide es auf die gleiche größe wie das eingangsbild und nehme das dann zusammen mit dem gleichen text als eingabe, um das nächste bild zu erzeugen. und immer so weiter. natürlich automatisiert mit meinem script oben, nicht per hand. aus all den bildern lasse ich mir am ende ein video erstellen:
beispiel halluzinierte katze
("a funny cat covered in neon cloth and neon light", seed = 1, guidance_scale = 8.5, strength = 0.5, num_inference_steps = 50)
weil das eingangsbild ja nicht jedesmal gleich ist, hindert das stable diffusion am einfrieren. die farben reduzieren sich zwar auf ein paar grundfarben, aber das finde ich cool, weil es die halluzination künstlerisch unterstreicht. es gibt inzwischen auch open source werkzeuge, die das alles schöner können, aber die sind aufwändig zu konfigurieren. meine "zoom" videos kommen mit ein paar trivialen zeilen python aus.
ein sehr ähnliches video, nur mit hund, etwas anderem text und wenn man die farben jedes eingangsbildes in grautöne umgewandelt:
beispiel halluzinierter hund
("a funny dog covered in cloth", seed = 1, guidance_scale = 8.5, strength = 0.5, num_inference_steps = 50)
gustave dore (1832 - 1883) und nacktheit bringt künstlerischen anspruch ins spiel, obwohl ich das mit den katzen- und hundevideos ja eigentlich vermeiden wollte:
beispiel halluzinierte künstlerische nacktheit
("artistic nudity in the style of gustave dore", seed = 1, guidance_scale = 8.5, strength = 0.5, num_inference_steps = 50)
die liste der bilder hab ich diesmal umgedreht (images.reverse() vor zeile 28 schreiben), so daß das daraus gemachte video quasi rückwärts läuft. also rauszoomt. ich bin so ein programmierkünstler. außerdem weise ich darauf hin, daß ich als eingabe nichts weiter als "nacktheit" geschrieben habe. das in dem maschinentraum praktisch nur frauen auftauchen liegt ausschließlich an dore. war halt eine andere zeit damals : )
stabiler und nochmal trippiger wird es, wenn man immer ...
beispiel halluzinierte künstlerische nacktheit 2
("artistic nudity in the style of gustave dore", erster seed = 1, guidance_scale = 8.5, strength = 0.5, num_inference_steps = 50)
ich hoffe die rechenkerne in meiner grafikkarte nehmen von der LSD artigen rechnerei keinen schaden. egal. hier noch etwas passende musik dazu .

ein sehr naheliegender trick ist noch, dinge im text besser zu definieren. "in farben eines ölbildes von 1890" hat genau den einfluß. "anatomisch realistisch" funktioniert auch, allerdings kann stable diffusion das noch nicht durchgehend. die nächste version 1.5 soll aber genau darin wesentlich besser sein. nur gibt es die heute (am 15. oktober 2022) noch nicht für das fußvolk.
beispiel halluzinierte künstlerische nacktheit 3
("anatomically realistic nudity in colors of an 1890 oil painting in the style of john william waterhouse, high details", erster seed = 1, guidance_scale = 8.5, strength = 0.5, num_inference_steps = 50)
psychedelische motive wie engel klappen übrigens auffällig gut, denn es ist vermutlich leichter von traumsachen zu träumen als von realen dingen:
beispiel halluzinierter engel
("an angel in colors of an 1890 oil painting in the style of gustave dore, high details", seed = 1, guidance_scale = 8.5, strength = 0.5, num_inference_steps = 50)
"kinderzeichnung von einem schloß" interpretiert die software teilweise als "kinder zeichnen ein schloß", was das ergebnis nochmal interessanter macht:
beispiel halluzinierte kinderzeichnung
("children drawing of a castle in a forrest next to a river", seed = 8, guidance_scale = 8.5, strength = 0.5, num_inference_steps = 50)
ich finde, das ist schon ziemlich stabil. in zwei jahren wird das total oll wirken, aber heute scheint mir das alles fantastisch. man kann die zukunft von aus text erzeugten videos förmlich riechen.
meine tips dazu:
der text muß sowohl allgemein genug als auch präzise genug sein, damit stable diffusion viel davon "erkennt". eine katze klappt super, weil deren fell ja gestreift sein kann. und das ganze funktioniert nur für manche einstellungen. wenn man etwas davon verändert kommt was komplett anderes raus. auch zusätzliche farbänderungen und zusätzliches minimales verrauschen der jeweiligen eingangsbilder haben starken einfluß, genau wie änderungen an der vergrößerung, drehung und verschiebung. wildes ausprobieren macht spaß, aber ich rate von allzu aufwändigen optimierungen ab, weil es garantiert demnächst eine durchdachte stabile open source lösung dafür gibt. ich denke, daran arbeiten gerade weltweit sehr viele kluge leute, denn das ist vermutlich das heißeste, das es derzeit gibt.
fazit
ich finde das ganze nach wie vor UNGLAUBLICH.
und das interessante ist dabei gar nicht mal nur die software, das datenmodell oder das grandiose berechnungsprinzip, sondern die frage, warum mir das als mensch so unglaublich vorkommt. ich vermute, daß da große anteile von chauvinismus mit im spiel sind. als so'n mensch kann ich einfach nicht verstehen, warum ein algorithmus kann was ich kann, wenn ich träume. und schon gar nicht wie die komplette visuelle welt in 4,2 gigabyte (die meine mittelgute grafikkarte geladen kriegt) passt. das datenmodel hätte ich mindestens tausend mal größer geschätzt. die kostenlose open source verteilung von einem so fetten datenmodell und der software ist jedenfalls ein echter meilenstein.
nachträge
neue diffusers releases gibt es unter github.com/huggingface/diffusers/releases
| hauptseite - ich - knabe - phylax - berlin - réflexions - satz - pornographie - schwäbisch - neu&sonst - scan - aktzeichnen - gästebuch - gesagt - maus - themenabend - verkehr - interview - chance - körper - marathon - pferdeohren - kampf - desicco - idee - fett - fahrrad - 3d - nestbau - rezepte - mytube - arcade - impressum |
|